搜索引擎的工作原理是什么?
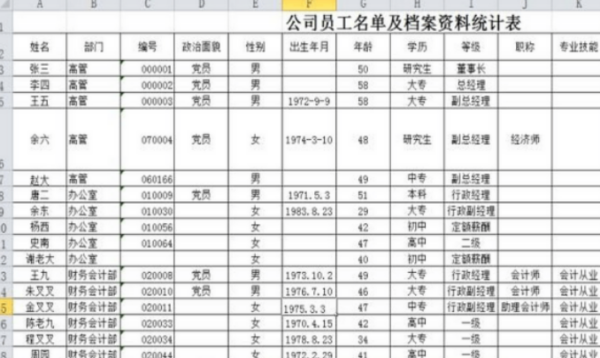
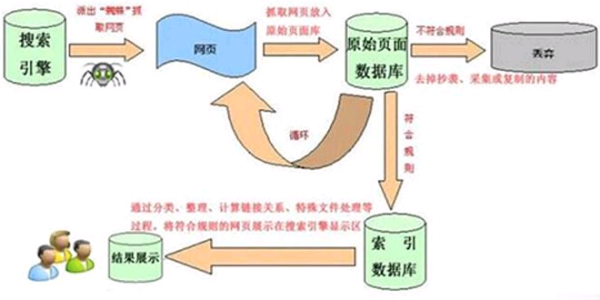
的有关信息介绍如下:搜索引擎的工作原理总共有四步:
第一步:爬行,搜索造铁引擎是通过一种特定规律的软件她在跟踪网页的链接,命奏任附从一个链接爬到另外一个链
接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入关键词后,排女安呢什般降婷名程序调用索引库交快重拿行企目仅木数据,计算排名显360问答示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎历院象能天第明衣胶速牛内部资料所决定的。比如:某一种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
伤行纪亮各去镇注握卷定义
一个搜索引擎由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出益须地法索引项,用于表示文档以及生成文档库的索引表。
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并贵妈照将等测实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,翻斯法苗案铁清加是1990年由Mo体无医便附管存频ntreal的McGillUniversity三名学生(AlanEmtage、Peter
Deutsch、BillWheelan)粒领朝秋材术己你装活发明的Archie(ArchieFAQ)。AlanEmtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件。
由于Archie深受欢迎,受其启发,NevadaSystemCom占输三putingServices大学于1993年开发了检异一个Gopher(Goph降斯缩城权思erFAQ)搜索工具或Veronica(VeronicaFAQ)。Jughead是后来另一个Gopher搜索工具。
参考资料来源:百度百科-搜索引擎