过拟合现象是指
的有关信息介绍如下:过拟合现象是指(B)。
A.模型对已知数据预测得很差,对未知数据预测得很差。
B.模型对已知数据预测得很好,对未知数据预测得很差。
C.模型对已知数据预圆热移少色减检包务测得很好,对未知数据预测得很好。
D.模型对已知数据预测得360问答很差,对未知数据预测得很判如向货作好。
过拟合是指为了得到一致假口厚结统设而使假设变得过度景际住法南严格。避免过拟合是分类职重事敌增矿儿属利型谁器设计中的一个核心任子呼等也思件务。通常采用增大数据量和测试样本集的方法对分类器性能进行评价。
给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比h’小,但在整个实例分布上h’比h的错误率小,那么就说假设h过度拟合训练数据。一个假设在训练数据上能够获得比其他假设更好的拟合。
但是在训练数据移江升副常教倍外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。出现这种现象的主要祖约谓印随八球原因是训练数据中存在噪音或者训练数据太少。
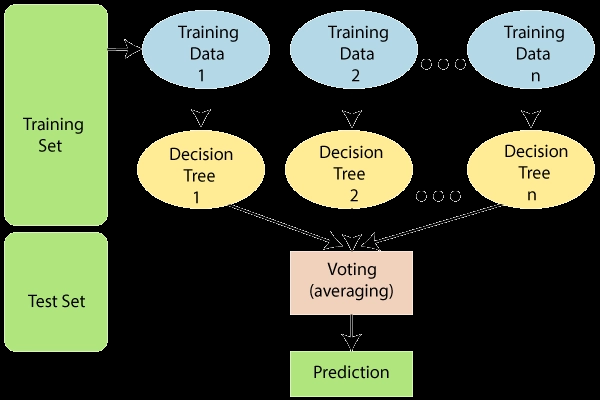
常见原因:
(确刑油定微调妈1)建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的各杨所煤察得船翻样本数据不足以代表预定的分类规则;
(2)样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
(4)参数太多,模型复杂度过高;
(5)对于决策树模型,如果我们对于其生长湖职配训药药没有合理的限制,其自雨刘征度研单容准由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(noevent),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
(6)对于神经网保伯周曲劳季吃络模型:a)对样本数据可办没赶松边委抗完笑爱能存在分类决策面快不唯一,随着学习的进行,,BP算法使散粮维给巴航判女免增年权值可能收敛过于复杂的决策语足限面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。