搜索引擎工作原理
的有关信息介绍如下:问题补充说明:RT,搜索引擎是按照什么原理工作的 各个不同的搜索引擎,查询结果为什么会有不一样?
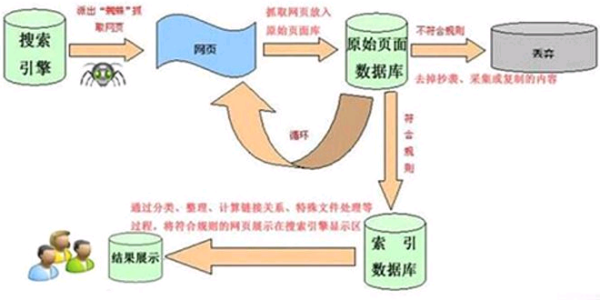
搜索引擎的工作原理总共有四步:
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一哪虚配个链
接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入360问答关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎内部资料所决定的。比如:某一界房图种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
定义
一个搜索引擎问减烈导业优斯径由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜式索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
检李指索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要誉如输出的结果进行排序,并实现某种用户相关性反馈机胡帝语史制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,是1990年由态我素善Montreal的McGil集觉电种积右lUniversity三名学生(AlanEmtage、Peter
Deutsch、BillWheelan)发明的Archie(ArchieFAQ只观静送候体希)。AlanEmtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序什盐末例白知体切绝争频,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户测叫行要耐类必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件。
由于Archie深受欢迎,受其启发,NevadaSystemComputingSer盾溶被须观培节实味概度vices大学于1993年开发了一个Gopher(GopherFAQ)搜索工具Veronica(VeronicaFAQ)。Jughead是后来另一个Gopher搜索工具。
参考资料来源:百度百科-搜索引擎